robots.txt是什麼? robots.txt設定、用途與使用範例分享!






適文
15 min read
2024-08-01更新
# 技術SEO
# SEO優化
# SEO做法
robots.txt vs meta robots 差異?robots.txt 設定怎麼做?本文將介紹 robots txt,並分享 robots.txt 範例,以及 robots.txt 測試工具!最完整的 robots.txt 教學就看這!
robots.txt 是什麼?超詳盡概念、用途、規則介紹!
之前的文章曾提過 Google 在新網站架設後會先經過檢索 Crawl 與建立索引 Index,後續才會進入 SEO 排名競爭行列(還不了解的讀者可以先查看:「SEO是什麼」這篇文章!)
那今天如果你的網站剛好有這些問題,例如:
- 有網頁正在進行測試,或部分網頁還沒建立完成
- 內容重複性太高,或是被索引對網站沒有幫助,例如後台
- 內容可能會對 SEO 排名有不良影響,例如內容相同但網址不同的兩個頁面
那是不是可以請 Google 不要對這些網頁建立索引呢?今天就來跟大家聊聊關於 robots.txt Google 是怎麼運作的,也教大家如何使用。
(一)何謂robots.txt?是機器人還��是文檔?robots.txt 用途有哪些?
robots.txt 本身是一種含有特定規則的簡易文字檔,內容主要是告訴「搜尋引擎檢索器」你的網站上有哪些是「不要檢索」的頁面;robots.txt 用途主要是為了「避免龐大的資訊量影響網站的速度」,通常也有部分機率不會被索引或出現在搜尋結果頁面上。
1.為什麼 robots.txt 僅有部分機率「不會被索引」?
- 原因一:並不是所有的搜尋引擎都會支援 robots.txt 內的指令。
- 原因二:對搜尋引擎來說,robots.txt 只是參考,並沒有強制力。
- 原因三:每種搜尋引擎檢索器解讀指令的方式不同,遇到無法解讀的會忽略,導致指令無法全面實行。
- 原因四:如果別的網站上有連結到 robots.txt 封鎖的網頁,那檢索器還是會將封鎖的內容建立索引。
舉例來說,你有一個秘密,雖然 Google 跟你聊天(檢索)時你拒絕告知(使用 robots.txt )這個秘密,但A知道你的秘密,只要 Google 認識了 A,就可以從他口中得知並記住(建立索引)你的秘密。
所以如果真的有特定的網頁或內容完全不想要被搜尋引擎發現或索引的話,不建議使用robots.txt 封鎖的方式,使用 meta robots 可能會是更好的選擇,這項工具下面第二大段會談到。
2.robots.txt 的指令有包含哪些內容?
- 網頁:重要性較低或重複性質高的網頁
- 媒體:網站或網頁中的照片、影片、音檔
- 資源:網頁中不重要的指令碼或特定樣式等
3.提交 robots.txt 給 Google 是必備流程嗎?
答案:不是!
假如你的網站內容都能被 Google 檢索與建立��索引,那麼可以不用提交,讓 Google 檢索器依照習慣去檢索所有網頁並建立索引;如果有提交 robots.txt,Google 檢索器才會盡量依照你的指令去執行檢索流程。
(二)robots.txt 對 SEO 有什麼好處?4 大優點一次看!
集中爬蟲資源,提升重要頁面排名
robots.txt 可以指示搜尋引擎爬蟲不要爬取特定頁面或資料夾,例如:後台管理頁面、測試頁面、重複內容頁面等。 這樣做可以避免爬蟲浪費時間在不重要的頁面上,將爬蟲資源集中在對 SEO 有價值的頁面上,提升重要頁面的抓取和索引效率,進而提升排名。
避免重複內容,提升網站品質
網站上可能存在重複內容,例如:產品頁面的不同排序方式、相同文章的不同版本等。
透過 robots.txt 阻止爬蟲抓取重複內容,可以避免搜尋引擎將網站判定為低品質,進而影響整體排名。
保護網站隱私和安全
robots.txt 可以阻止爬蟲抓取網站上的敏感資訊,例如:用戶資料、後台設定等,保護網站隱私和安全。
避免浪費爬蟲爬取預算
每個網站都有「爬蟲預算」,也就是搜尋引擎分配給網站的爬取時間和資源。robots.txt 可以幫助網站有效利用爬蟲預算,避免浪費在不必要的頁面上。
robots.txt 怎麼做?使用 robots.txt 應該注意的 9 個項目!
(一)建立 robots.txt 的注意事項

- 請使用文書軟體(Word)以外的文字編輯器建立 robots.txt 檔案,例如:記事本、Notepad、TextEdit、vi和emacs等工具;至於文書軟體是由於容易因符號不相容而在檢索過程中出現問題,所以不建議使用。
- 內容必須以 CR、CR/LF 或 LF 分隔行列才有效,如果是無效的行列,Google會選擇忽略。
- 儲存 robots.txt 檔案時,必須選擇UTF-8編碼,並存成純文字檔案。
- 檔名必須是 robots.txt
- 目前 robots.txt 檔案的容量大小有強制規定,最多為 500KB ,一旦超過的話,Google 會選擇忽略那些超標的內容。
(二)放置或變更 robots.txt 的規則

- robots.txt 檔案必須放在網站目錄的最上層並設定公開。
- Google 若沒有辦法判定 robots.txt 的內容,例如檔案錯誤或本身就不支援,可能會直接忽略指令。
- 若要變更 robots.txt,可以在更新後重新提交給 Google,以加快程序。
- Google 收到 robots.txt 變更後的生效時間不固定,只能透過重新提交檔案來加快流程,沒辦法保證多久會好。
robots.txt 怎麼寫?7 大 robots.txt 撰寫範例分享
robots.txt 中的每個程式碼都有它代表的含意與指令,我們先從每一小區塊開始拆解,當所有的細節都了解後,撰寫就會變得很輕鬆!
(一)robots.txt 內容包含什麼?5 大內容解析!

- User-agent:填寫檢索器的名稱,看是針對個別對象(Googlebot、bingbot、Yahoo! Slurp等)��還是所有檢索器(用「*」表示)都共用,字母大小寫沒有限制。
- Allow:必須填寫完整路徑,告訴檢索器哪些網頁或檔案內容歡迎檢索,指令的大小寫會有影響。
- Disallow:必須填寫完整路徑,告訴檢索器哪些網頁或檔案內容不希望它來檢索,指令的大小寫會有影響。
- Crawl-delay:可設定檢索器來訪的最短時間間隔秒數,必須以阿拉伯數字填寫。
- Sitemap:填寫 Sitemap 檔案的完整路徑,有區分大小寫。
(二)robots.txt 撰寫案例
所有的檢索器都可以檢索全部網站內容:
- User-agent: *
- Allow:/
所有的檢索器都不能檢索全部網站內容:
- User-agent: *
- Disallow:/
特定的檢索器可以檢索全部網站內容(以Googlebot為例):
- User-agent: Googlebot
- Allow:/
特定的檢索器不可以檢索全部網站內容:
- User-agent: Googlebot
- Disallow:/
特定檢索器可以檢索特定的網站內容:
- User-agent: Googlebot
- Allow: /images/
- Allow: /private/
所有檢索器都不能檢索特定路徑的網站內容:
- User-agent: *
- Disallow: /images/
- Disallow: /private/
特定檢索器不能檢索特定路徑的網站內容:
- User-agent: Googlebot
- Disallow: /images/
- Disallow: /private/
基本上不會特別寫「全部檢索器可以檢索所有網站內容」,因為這是檢索器本來就�會做的事情。
robots.txt 測試工具怎麼用?9 步驟學會 GSC 測試工具!
當建立好 robots.txt 檔案並上傳到網站後台後,如果想要檢測自己的 robots.txt 有沒有問題、是不是成功的封鎖了檢索器,可以利用 [Google Search Console](https://welly.tw/blog/how-to-use-google-search-console) 提供的「robots.txt 測試工具」來進行測試。
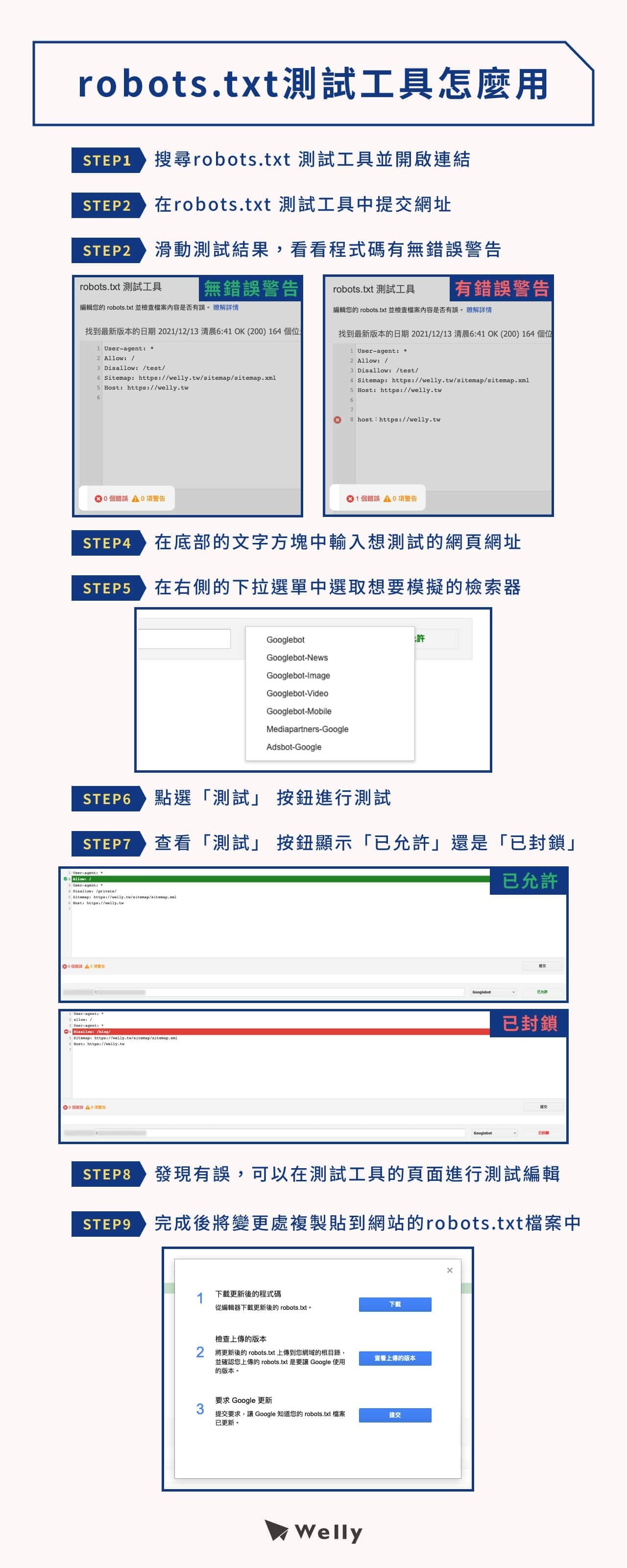
- STEP 1:首先搜尋 robots.txt 測試工具並開啟連結
- STEP 2:在 robots.txt 測試工具中提交網址
- STEP 3:滑動測試結果,瀏覽 robots.txt 程式碼有無錯誤警告
- STEP 4:在網頁底部的文字方塊中輸入想測試的網頁網址
- STEP 5:在右側的下拉選單中選取想要模擬的檢索器
- STEP 6:點選「測試」 按鈕進行測試
- STEP 7:查看「測試」 按鈕顯示「已允許」還是「已封鎖」
- STEP 8:如發現有誤,可以在測試工具的頁面進行 robots.txt 檔案的測試編輯
- STEP 9:調整完後將變更處複製貼到網站的 robots.txt 檔案中
請注意:robots.txt 測試工具僅提供檢測功能,即便編輯也不會對檔案做出實際上的更動,所以在測試工具上調整完後一定要記得修改原本上傳到網站後台的 robots.txt 檔案才會生效。
meta robots 是什麼?與 robots.txt 差異比較表分享!
接下來要介紹的 Google meta robots 是另一項工具,會有人搜尋「html meta robots」是因為它的程式碼像 html,雖然看起來非常簡單,但是指令背後的涵義與排列組合必須要全盤了解後才能充分掌握,至於它與 robots.txt 的差異下面也會進行說明!
(一)保護網頁的秘密武器:探索 meta robots 的好用功能!
相較於 robots.txt 限制 Google 等檢索器進行「檢索」,meta robots 則是更明確下令「不准建立索引」,也就是即便 Google 爬到該網頁,也不會將內容建立索引,就不用怕自己的網頁會出現在搜尋結果。
不過要使用 meta robots 也相對較費力,必須要在「不想被建立索引的網頁 head 底下」手動新增相關標籤,有幾個頁面需要封鎖,就要手動添加幾次!
針對這幾個點,我們可以整理出 robots.txt 與 meta robots 的比較表:
| robots.txt | meta robots | |
|---|---|---|
| 主要功用 | 防止檢索器「檢索」特定網頁或資訊內容 | 防止檢索器對特定網頁內容「建立索引」 |
| 撰寫方式 | 使用文字編輯器撰寫成robots.txt後上傳到網站 | 新增在該網頁的head下方 |
| 使用程式碼 |
(二)簡單快速上手!meta robots 程式碼功能解析與範例!

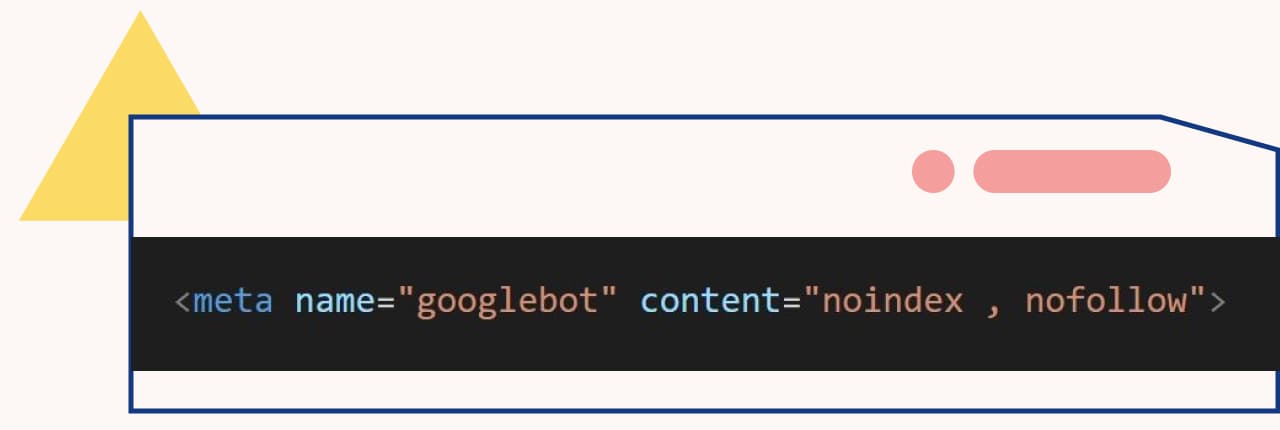
- meta name:填寫檢索器的名稱
- content:填寫網頁是否允許建立索引�,下令 meta noindex 或是 index nofollow 等
- index:允許建立索引的頁面就下令 meta robots index 網頁
- noindex:下令 meta robot noindex 就可以禁止它建立索引
- follow:有些內容會加入同網站其他網頁或不同網站的連結,如果沒有下令 meta robots nofollow,Google 就可以追蹤該網頁上的連結
- nofollow:只要下令 meta nofollow,就等同禁止追蹤該網頁上的連結
(更多 nofollow 介紹,歡迎參考:《nofollow是什麼?不想權重被瓜分?這項SEO技術非懂不可!》)
(三)meta robots 撰寫範例
- 下令 meta robots index follow,表示允許建立索引與追蹤連結,但即便沒有特別下令 meta index follow,根據預設值,檢索器也會做這個選擇。
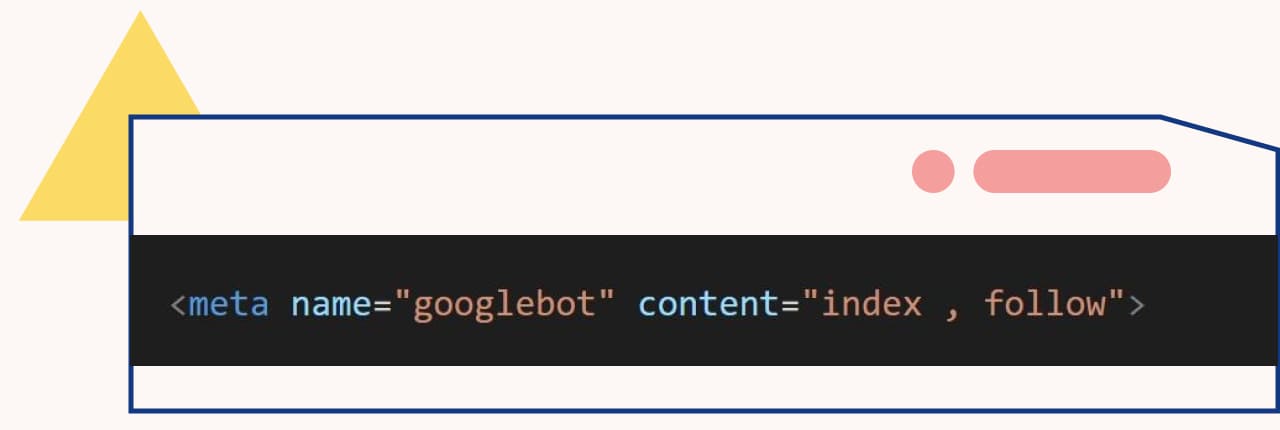
- 只下令 meta no follow,表示雖允許建立索引,但不允許追蹤連結
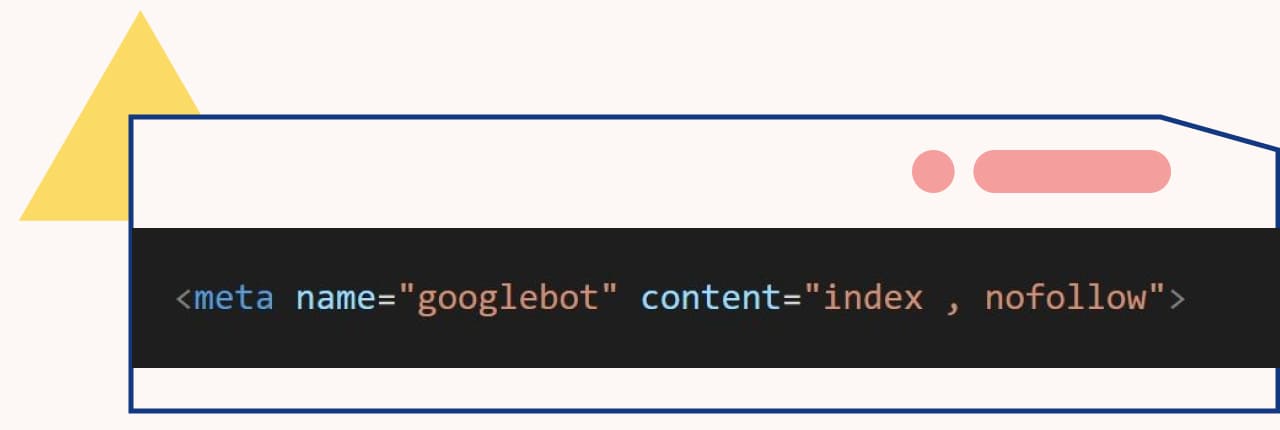
- 只下令 noindex,表示雖該頁面不允許建立索引,但網頁中的連結可以正常追蹤及建立索引
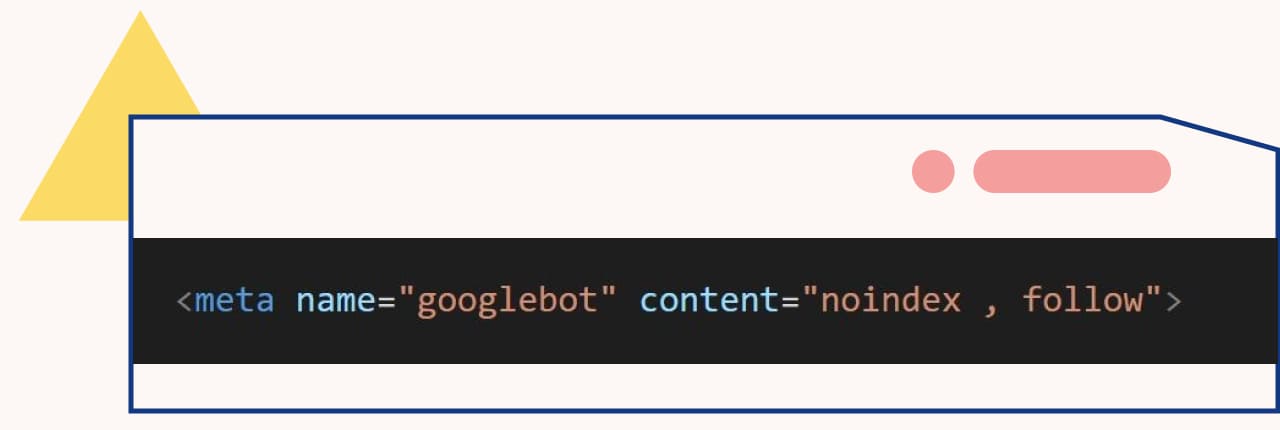
- 下令 noindex nofollow 就是從建立索引到追蹤連結都不允許
以上就是 meta robots 程式碼的相關資訊,如果你有其他指標或工具使用上的疑問,或者不確定自己的 SEO 報告該怎麼解讀,甚至希望專人為你分析,都歡迎點擊下方立即諮詢按鈕,Welly 團隊會有專員為您服務!
適文
創辦人兼執行長
分享至












