Noindex是什麼?了解3種設定方法與使用時機,讓你提升網站排名!






Kira
17 min read
2024-11-11更新
# SEO優化
# SEO概念
# SEO排名
Noindex是什麼?對SEO排名有哪些重要性?如何設定Noindex?本文將詳細介紹Noindex,並比較常見的SEO技術面方法,最後提供Noindex測試工具,優化網站排名!
SEO 技巧大公開!深入解析 Noindex 與搜尋引擎的關係
你已經優化了網站內容,卻發現網站排名不如預期嗎?這時候可以回過頭來檢視,在架設網站的時候,是否有根據搜尋引擎的爬取設定、優化?因為 SEO 的排名仰賴搜尋引擎的運作,所以這部分絕不可忽略!
那搜尋引擎是怎麼運作的呢?怎麼影響 SEO 的排名?又該如何設定?下文將跟你仔細介紹搜尋引擎執行的過程,以及 Noindex 在其中扮演的重要角色。
(一)什麼是 Noindex?從搜尋引擎的爬取和索引機制說起
我們先來了解 Google 搜尋引擎運作的流程,可以簡單分為 3 個階段:
- 檢索網站
- 建立索引
- 呈現搜尋結果
接著再來詳細介紹什麼是爬取和索引:
檢索/爬取(Crawl)
此階段為 Google 在廣大的資訊海中,只要發現新頁面(或更新的網站),就會將它看到的所有資訊打包起來,列入等待索引的清單。
建立索引(Index)
接著 Google 會仔細��分析爬取到的所有資料,包含架構、內文、圖片以及程式碼等,如果它認為內容有價值,就會收錄到資料庫中。當使用者進行關鍵字搜尋時,瀏覽器會依據索引存放的資料挑選相關的資料。這一步便會影響你的網頁是否會出現在推薦搜尋上,對於 SEO 排名至關重要!
請注意:並不是索引的資料越多,對於 SEO 的排名越有幫助。如果有過多不相關或降低使用者體驗的網頁被索引,有可能會被 Google 判定為較低價值的網站,排名也會下降。
因此當我們有不想出現在搜尋推薦的頁面,或者想避免不重要的頁面被索引而影響 SEO 排名,同時希望保留可能提升 SEO 排名的頁面,讓搜尋引擎爬取。這時就需要好好運用 Noindex 管理網站。
看到這裡你可能會疑惑: Noindex 是什麼?
Noindex
Noindex 顧名思義是「不要被索引」。它屬於 HTML 語法中的一個標記(Tag),只要在特定網頁設定了 Noindex 標記,搜尋引擎就不會索引該網頁,也不會出現在搜尋頁面上。
常見的語法標記為:
<meta name="robots" content="noindex">
(二)Noindex Link 使用時機有哪些?
在實際情況中,什麼時候會使用到 Noindex Link 呢?以下將 Noindex Link 使用時機分為 3 種:

1. 對 SEO 排名無幫助的頁面
這類是被要求或希望停留在網頁中的資訊,需要被爬取,但出現在搜尋頁面上對 SEO 排名沒有幫助,也很容易累積過多被下降整體排名。
範圍較廣,大致可以分為這 4 類:
- 法律頁面:條款、聲明
- 重覆頁面:包含相同內容的頁面
- 錯誤的頁面:404 錯誤頁面、系統頁面
- 過期的頁面:有時效性但希望留在網頁紀錄中(商品、廣告)
2. 不公開頁面
包含網站內屬於後臺的資料,或需特定使用者才能看到的頁面,例如登入畫面、使用者資料、購物車內容等。這些不希望被公開的資料,就能使用 Noindex Link 保障隱私。
3. 未完成的頁面
半完成、還在測試階段的網頁都屬於未完成的頁面,不應該出現在搜尋頁面中,因此需要使用 Noindex Link ,防止被索引。
(三)Noindex 對 SEO 的重要性為何?2 大好處一次看!
了解完 Noindex 的使用時機和功能後,我們可以將 Noindex 對 SEO 的好處整理成以下 2 個部分:
1. 提升網站內容品質
Noindex 主要功能在於限制搜尋引擎收錄,因此可以排除網站中不重要或重覆的內容。透過這種方式,可以讓網站集中在高品質和有價值的頁面,避免被搜尋引擎判定為低品質,降低排名。
2. 防止使用者體驗降低
如果搜尋引擎收錄過多不重要的網頁,會令使用者在搜尋關鍵字時,跑出過多不相關的頁面,容易找不到主要內容。適當地使用 Noindex 調整,可以讓搜尋引擎能專注在主要內容,降低使用者的負擔。
如何設定 Noindex?3 種方式供你輕鬆使用!
那 Noindex 該如何設定呢?根據 Google 說明文件, Meta 標記和 HTTP 回應標頭是兩種常見的設定方法。另外,當我們使用 Wix、WordPress 或 Blogger 等網站時,則需使用外掛修改。接下來將仔細介紹 3 種不同的修改方式,你可以依據遇到的不同情況,挑選最適合的方法。

(一)從 Meta 標記直接設置 Noindex
Noindex 屬於 Meta Robots,也就是設定在 HTML 語法一種標籤。
Meta 是指網頁中的元資料,呈現網頁的完整數據與內容。Meta Tag 則是元標籤,能讓搜尋引擎更快速地掌握網頁資訊,通常放在網頁 〈head〉 之下。其中 Meta Robots 是特定的 Meta Tag ,讓所有或是特定搜尋引擎知道如何處理網頁。
因此我們可以直接在特定網頁設定中的 〈head〉 標籤底下加入以下語法:
<meta name=”robots” content=”noindex”>
如果我們要進行更細部的調整,那就需要認識 Meta Robots 主要指令欄位:
- Meta Name: Meta robots 設定的搜尋引擎
一般設置「robots」,就是套用所有的 Google 搜尋。根據不同情況,也可以只限制特定的搜尋引擎,將「robots」替換掉即可。以下分享常見的搜尋引擎:
| 搜尋引擎 | Meta Name |
|---|---|
| 所有搜尋引擎 | robots |
| Google 搜尋 | googlebot |
| Google 圖片 | googlebot-image |
| Yahoo | slurp |
| 百度 | baiduspider |
所以當我們想要百度引擎禁止檢索的話,語法會寫成以下方式:
<meta name=”baiduspider” content=”noindex”>
語法中的「Content」則是代表 Meta Robots 的設��定內容,Index、Noindex 都可以在此設置,包含後面會提到的 Nofollow 和 Follow。
(二)由 HTTP 回傳 Noindex
第二種方式則較為複雜,需要擁有網站的管理權才能設置。如果要禁止系統為非 HTML 資源建立索引 (例如 PDF 檔、影片檔或圖片檔),就要用 HTTP 回應標頭的方式設定。
這時候我們要在伺服器端用 X-Robots-Tag 做為回應標頭,在後面輸入 Noindex,告訴瀏覽器不要索引頁面,例如:
HTTP/1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
在上面範例中,可以看到 HTTP 開頭一定有狀態碼,範例中 200 OK 代表我們請求成功,網頁內容可以顯示。(…) 以下為伺服器回應我們請求的內容,標頭後提供額外的訊息,比如網頁的類型、大小、是否可以被搜尋引擎索引等,因此我們要在之中增加 X-Robots-Tag ,輸入「noindex」就成功了!
(三)其餘 SEO 外掛程式
如果你使用的是 Wix、WordPress 或 Blogger 等網站,那就不能使用上面兩種方式修改,必須藉由其他的外掛程式增加標籤。不過常見的 SEO 外掛程式都有內建此功能,不用太過擔心。以下以 WordPress 中的 Yoast SEO 外掛為例:
設定路徑:
- 點選單篇的編輯內容
- 下滑找到「進階」欄位
- 看到「允許搜尋引擎在搜尋結果中顯示這篇內容」
- 選擇「否」

SEO 技術比較:Nofollow、Noindex 與 robots.txt 的差異分析
提到 SEO 優化方式的時候,你一定還會聽過 Nofollow 和 robots.txt 兩項工具,這跟我們介紹的 Noindex 有什麼差別呢?下文會從使用時機和功能開始比較差異,最後附上表格讓你輕鬆搞懂該如何使用!
(一)Nofollow、Noindex 差在哪?
Nofollow 是什麼?在 SEO 中有什麼作用?
Nofollow 和 Noindex 皆屬於 Meta Robots 的一種標籤。Nofollow 主要功能是告知伺服器不要追蹤連結網址,因此會讓搜尋引擎索引,也會出現在搜尋結果上。對於 SEO 最大的作用則是避免分掉網站權重。
Noindex 與 Nofollow 3 種不同情境案例、對應語法分析
之前說明 Meta Robots 內可以針對各種的要求修改限制,包含上面介紹的 Nofollow 和 Noindex。那麼實際該如何運用呢?哪些頁面需要使用不同的語法調整?下面我們整理了 3 種不同的情境與對應的語法撰寫:
1. Noindex Follow:告訴搜尋引擎不要索引這個頁面,但可以追蹤所有連結
當網站中出現相似、重覆或不重要的頁面,其中可能包含有價值的連結。這些需要保留連結的權重傳遞,而不想讓他們出現在推薦結果頁的情況,便可以運用 Noindex Follow。
語法為:
<meta name=”robots” content=”noindex , follow”>
2. Index Nofollow:搜尋引擎可以索引這個頁面,但不要追蹤所有連結
大多開放評論、留言的網站。或者如 PTT、Dcard 等社群論壇,因為屬於自製網站,難以管理內容,也很難防止垃圾連結。所以需要設置 Nofollow 避免降低權重,但其內容對搜尋頁面有幫助,因此不限制索引。
語法為:
<meta name=”robots” content=”index , nofollow”>
3. Noindex Nofollow:禁止搜尋引擎索引這個頁面,也不要追蹤所有連結
當網站有過期��資訊、不公開的資訊、或者還在測試的頁面,這時我們不希望被搜尋引擎索引和追蹤連結,避免下降 SEO 排名,就可以用 Noindex Nofollow 限制。
語法為:
<meta name=”robots” content=”noindex , nofollow”>
通常不會設定 Index Follow,正常情況伺服器就會如此運行。
還是搞不懂 Nofollow?歡迎參考:nofollow是什麼?不想權重被瓜分?這項SEO技術非懂不可!
(二)robots.txt 是什麼?什麼時候會用到?
robots.txt 是包含特殊指令的文字檔,內容在告知網站哪些不要爬取(檢索),但允許索引,因此會顯示在搜尋結果頁面上。
除了因為有不想被網路爬取的內容會使用 robots.txt。當我們想集中網路資源時也會運用robots.txt,避免因為過多的資訊而降低網站速度,也可以降低網路的爬蟲預算。
詳細的 robots.txt 介紹,請看這篇文章:robots.txt是什麼? robots.txt設定、用途與使用範例分享!
(三)三者差異總整理
針對上面個別提到的特點,我們整理出了 Nofollow、Noindex 與 robots.txt 的比較表格:
►從 Google 角度分析
| 項目 | Nofollow | Noindex | robots.txt |
|---|---|---|---|
| 檢索 | 允許 | 允許 | 限制 |
| 索引 | 允許 | 禁止 | 允許 |
| SERP 顯示 | 允許 | 禁止 | 允許 (有被索引的會出現) |
►從實際運用層面比較
| 項目 | Nofollow | Noindex | robots.txt |
|---|---|---|---|
| 功能 | 禁止伺服器傳遞權值 | 禁止伺服器索引 | 限制伺服器爬取 |
| 使用時機 | 不願為其背書的網站連結 | 有重覆的、不重要的網頁內容 | 可能有對排名不利的內容 |
| 使用目的 | 避免權重被連結分掉 | 除去無助於排名的網頁 | 集中爬蟲資源 |
如何測試 Noindex?免費檢測工具分享:Google Search Console
當我們設定完 Noindex 之後,要如何測試網頁有沒有成功被索引呢?除了直接搜尋關鍵字,觀察網頁有沒有出現在推薦頁面上, Google 還提供了一項免費工具可以使用「Google Search Console」。
如果第一次使用 GSC,請先參考此篇文章:Google Search Console教學:GSC設定、功能完整教學!
根據之前文章驗證、安裝完之後,接著就來了解如何使用 Google Search Console!
步驟 1:在上方欄位輸入要檢查的網頁網址,並按下「Enter」鍵。
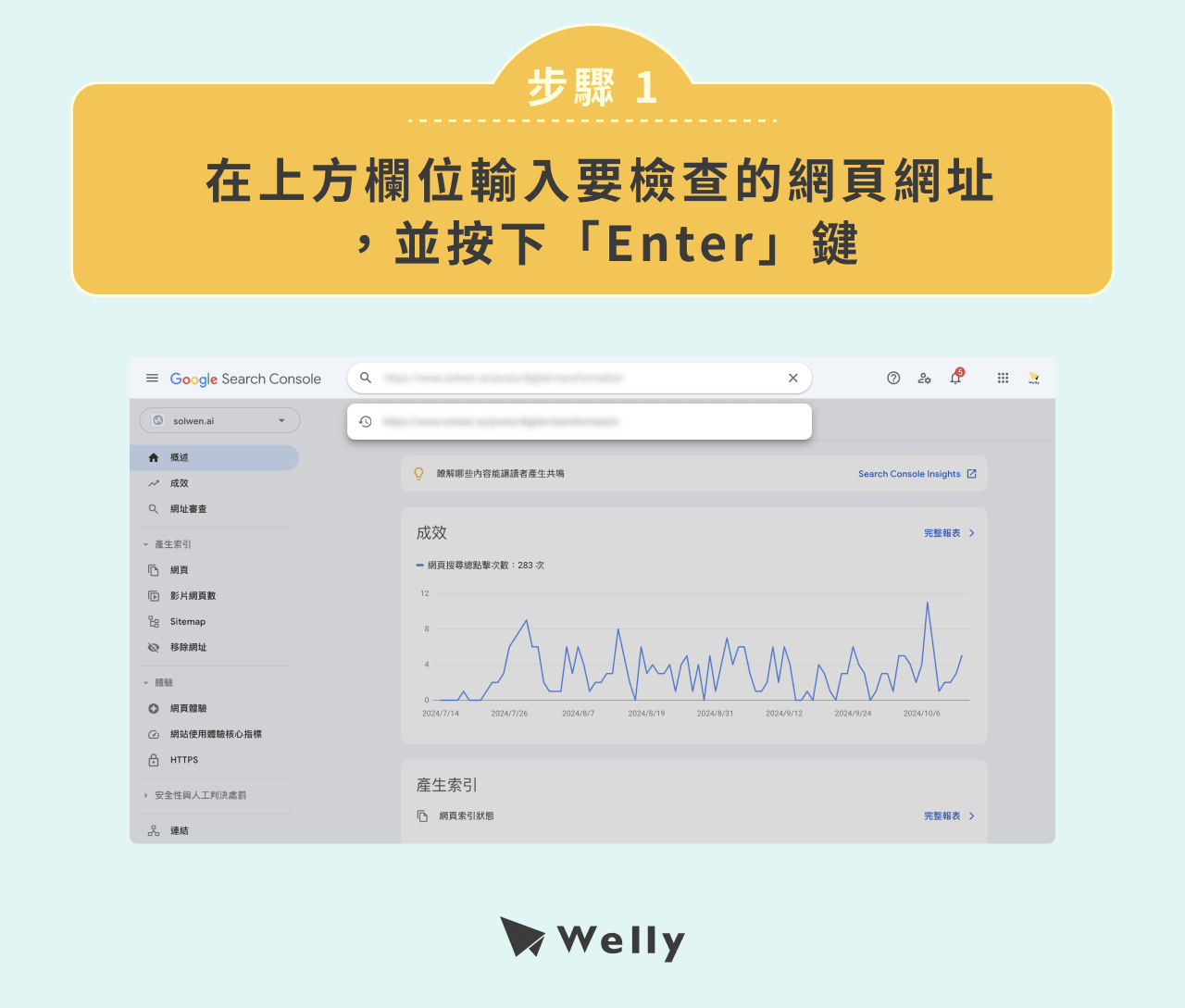
步驟 2:點選「測試線上網址」。
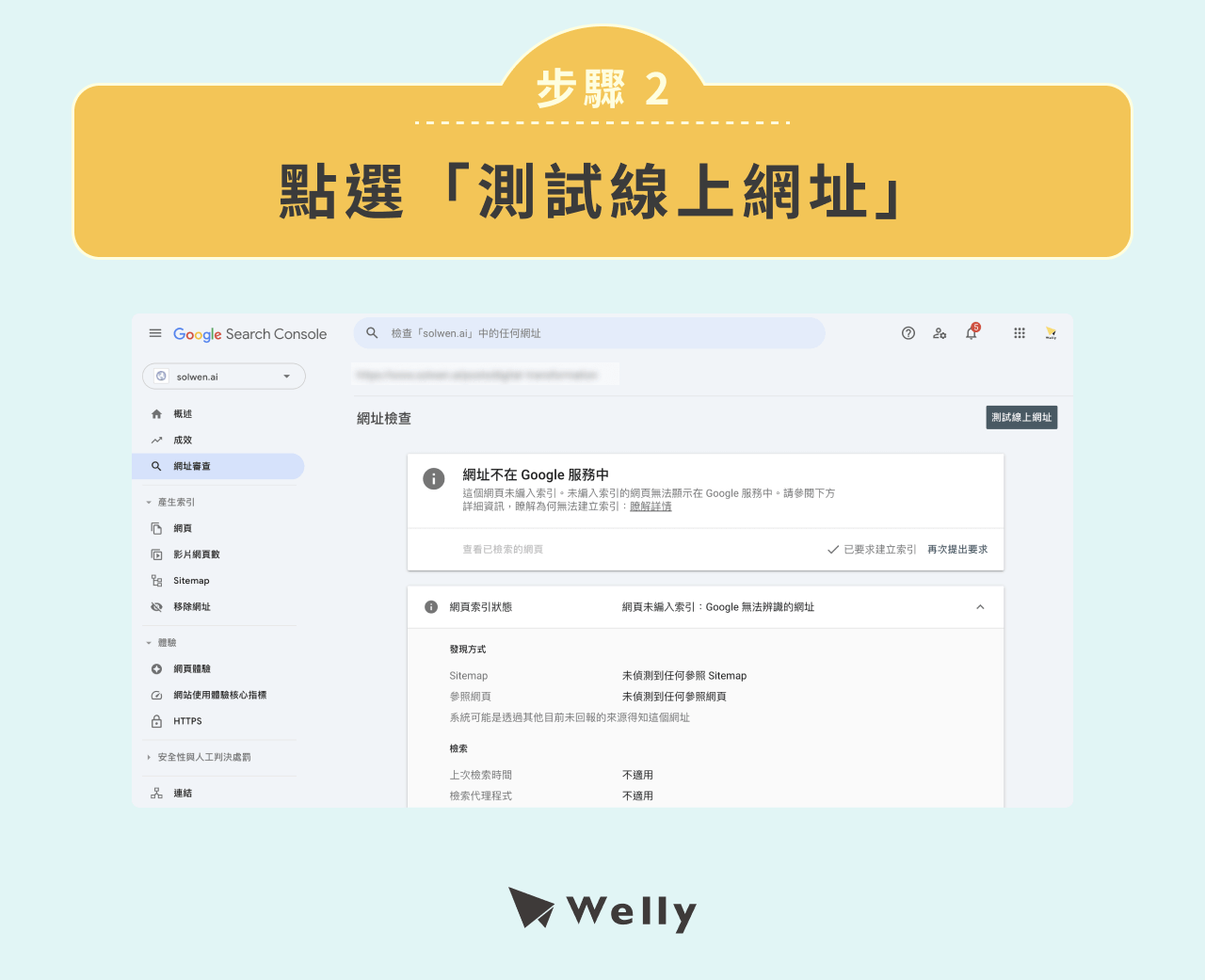
步驟 3:等待 GSC 加載。
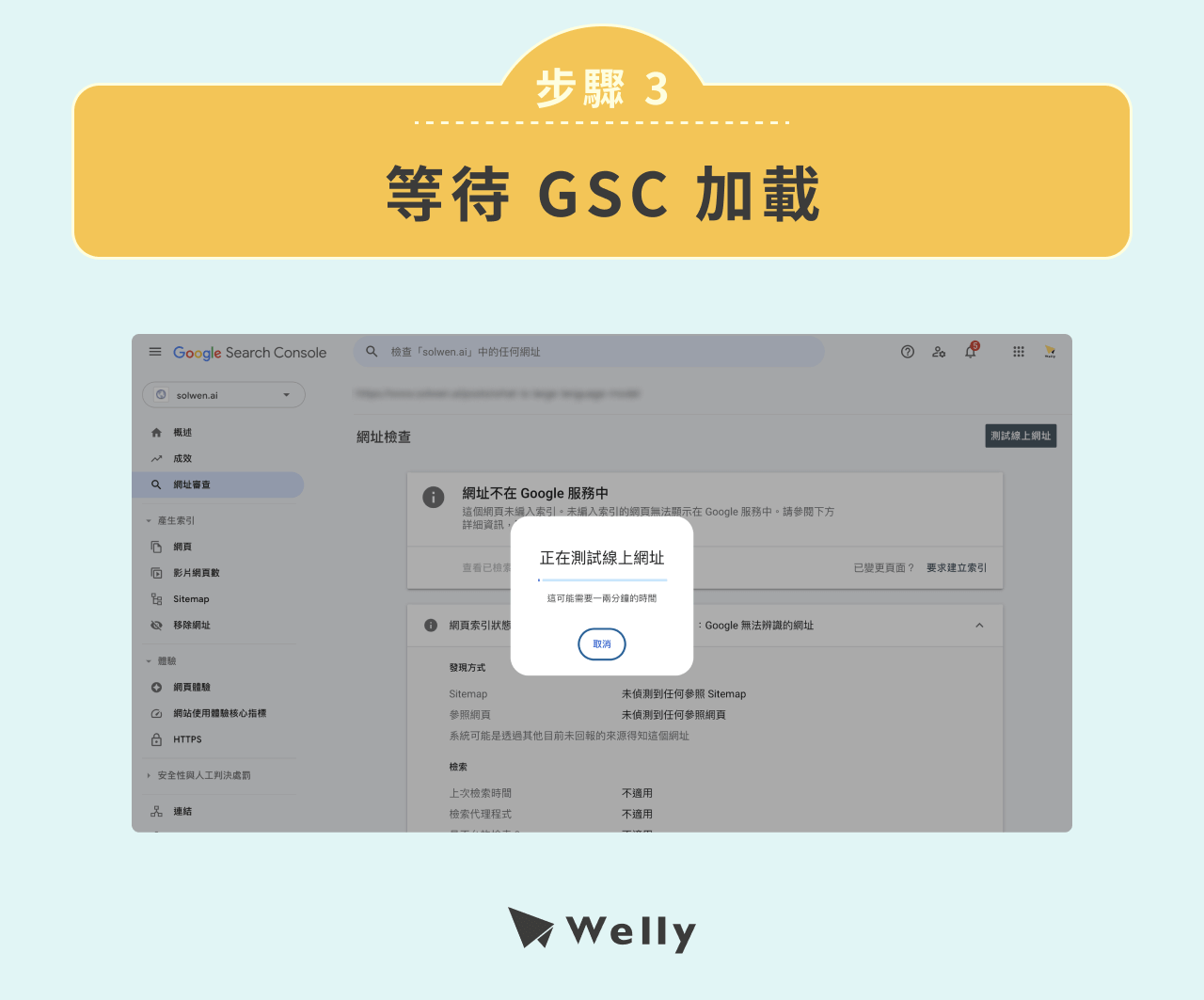
步驟 4:觀察「網頁可用性」處
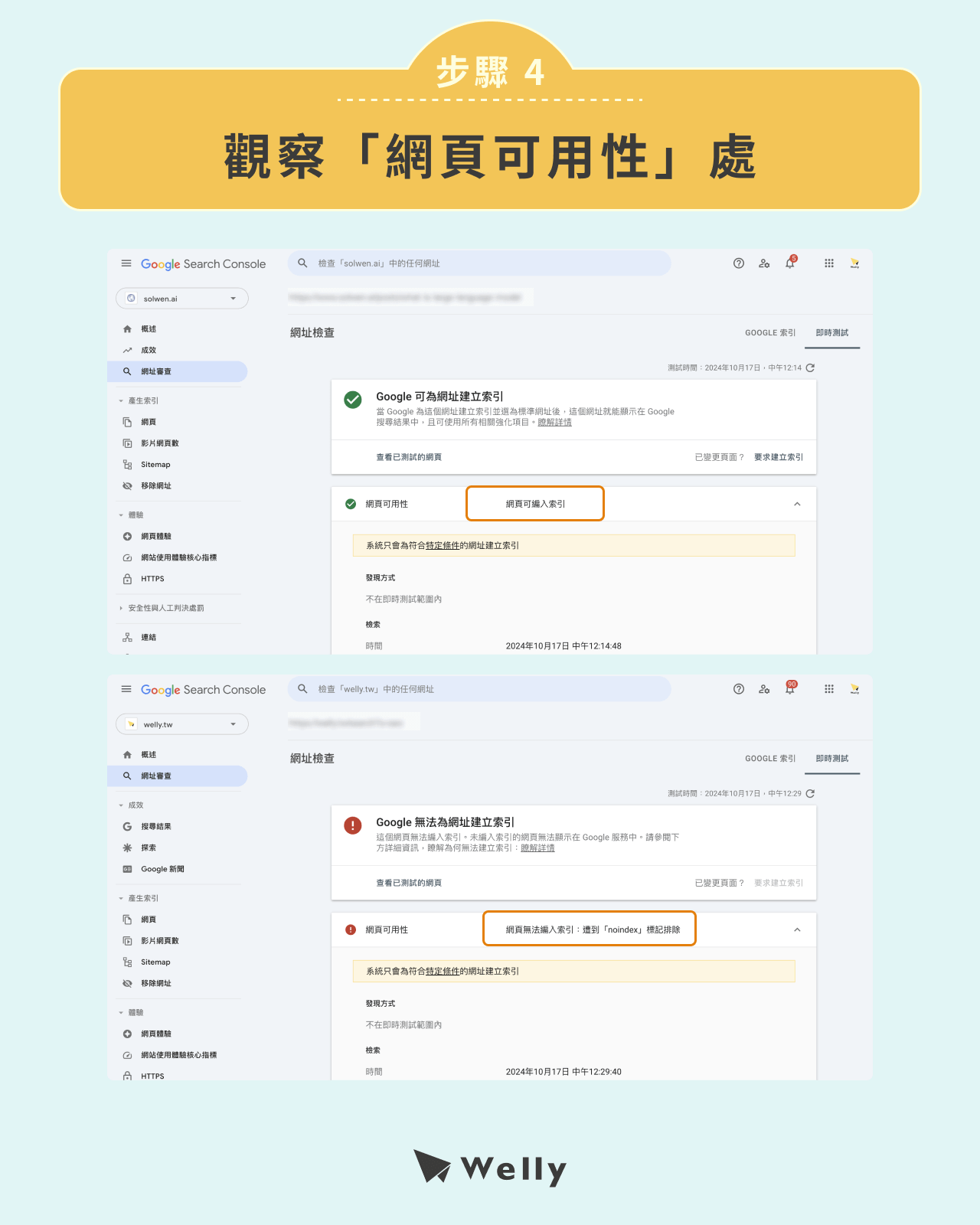
加載�完畢後,接著觀察「網頁可用性」處。
如果顯示的是「網頁可編入索引」,就代表網頁未設置 Noindex,或是我們並未成功設定 Noindex;如果你看到出現遭到「Noindex」標記排除,就代表網站成功執行 Noindex 了。
上圖顯示了我們對官網不同頁面檢測的結果。由於 Welly 官網上具備搜尋文章的功能,導致會有人在搜尋框惡意搜尋,試圖讓搜尋的網址「search?s=惡意內容」可以被索引,進而影響 Welly 的 SEO 排名。因此我們使用 Noindex ,將所有搜尋功能的網址設置為不被索引。
以上是 Noindex 的介紹,如果您想要了解更多 SEO 資訊,或者想要獲取免費的 SEO 健檢報告,都可以透過下方黃色按鈕與 Welly 團隊聯繫!
Kira
創辦人兼營運長
分享至





想收到 Welly 彙整的國內外行銷新知?
訂閱可以收到:
每週一篇新知報
一季一本電子書
SEO 系統性學習文











